First impressions: Mycroft voice assistant
I don’t get voice assistants. Telling computers what to do using my voice has never really appealed. Sure, they’re cool. And I admit they’re also super useful for some people. Just for not me.
In spite of this, I’m fascinated by the speech recognition and text-to-speech software behind these assistants, which, quite frankly, is incredible. Of course, it isn’t the most efficient way of interacting with computers, but when it works it’s magical. And we’re now at the point where it works pretty damn well. The fact that some inanimate box on a kitchen bench can understand my grunts, hisses and splutters as language, parse the resulting string and provide me a spoken answer (and possibly a week’s worth of groceries) leaves me taken aback.
It’s a shame then that only large, private tech companies have a foothold in the field. What makes it hard for anyone else to be a serious contender in the space is a lack of data. You need a lot of spoken data to train the models used in speech recognition. Sadly, this isn’t the space for underdogs.
Oh, hold up…
Enter an intellectually and ethically satisfying alternative: the Mycroft project. Which describes itself as:
…a suite of software and hardware tools that use natural language processing and machine learning to provide an open source voice assistant.
I’ve been interested in project for a while now. Here’s why:
- It’s open source
- It isn’t built by a major advertising company or online retailer
- It uses Mozilla’s Deep-Speech speech to text engine, which in turn uses the public domain Common Voice database as training data
- You can quickly get it up and running on a laptop or Raspberry Pi
So, partly in curiosity, partly in an attempt to improve the training data for free and open voice assistants, I picked up a Raspberry Pi, attached a mic and speaker and installed Mycroft.

Once I’d sorted a decent power supply, it was up and running in no time.
Before moving on, I should note that Mycroft isn’t ready for widespread adoption just yet: sometimes it runs into issues with hardware; its current skill set is quite limited; and it’s lacking in support for languages other than English. Right now it’s recommended for hackers and developers (and, presumably, linguistics nerds who don’t mind fiddling around at a command line). That being said, it’s definitely still usable, even useful - just don’t expect something as polished as a Google Home or Amazon Echo.
General impressions
Fun. After getting it up and running I was asking questions at the rate of a four year-old at the zoo.
- “What’s the height of Mt. Everest?”
- “What’s one cup of flour in grams?”
- “Who was the third Prime Minister of New Zealand?”
- And so on, ad nauseum.
And you know what? Mycroft was always on the mark. Although I was aware I was talking to a computer, I found I could speak fairly naturally and still be understood.
I don’t see myself using it to improve my everyday life any time soon. But, as I made clear at the start of this post, I’m more interested in the voice and less interested in the assistant aspect of the device.
In the next couple of sections I’ll cover some things that have stood out for me.
What’s the weather in Nagoya?
The speech recognition is good. Really good. Much more accurate than I expected. Mishearings are few and far between.
One thing that impressed me was when I asked Mycroft what the weather was in my nearest city, Nagoya. In English we stress the second syllable of this word, saying something like na-GOY-a. In Japanese, on the other hand, there’s no such thing as stress. Syllables can be pitch accented, i.e. the pitch is higher than other syllables in the word, but there aren’t the same changes in volume, duration and articulation that we have in English stressed syllables. Pitch accented syllables can sound stressed to English speakers, since pitch-raising is another feature of stress. However, what’s actually being produced is quite different.
Now, instead of na-GOY-a with stress on the second syllable, in Japanese the place name is pronounced NA-go-ya, with a pitch accent on the first. And over time I’ve gotten used to saying it the Japanese way. So when I asked, “What’s the weather in NA-go-ya?” and Mycroft gave me an appropriate response, I was duly impressed. All the more so because the typically English pronunciation begins with a reduced syllable [nə], rather than [na].
Wakeword (mis)recognition
On the flipside, there are times when Mycroft is just too keen. It thinks it’s being asked to do something when it isn’t.
When playing podcasts, Mycroft wanted to join in. Over the course of one 45 minute podcast, I noticed Mycroft’s “I’m-ready-for-a-command” chime crop up about half a dozen times.
Not a big deal, but a little annoying.
Making things better
So, given the project has made major inroads already, what would make it a real competitor?
Ultimately what makes voice assistants better is more data. More voices makes for better recognition and better recognition makes for a better user experience.
One way of contributing without setting up Mycroft for yourself is reading and verifying sentences for Mozilla’s Common Voice database.
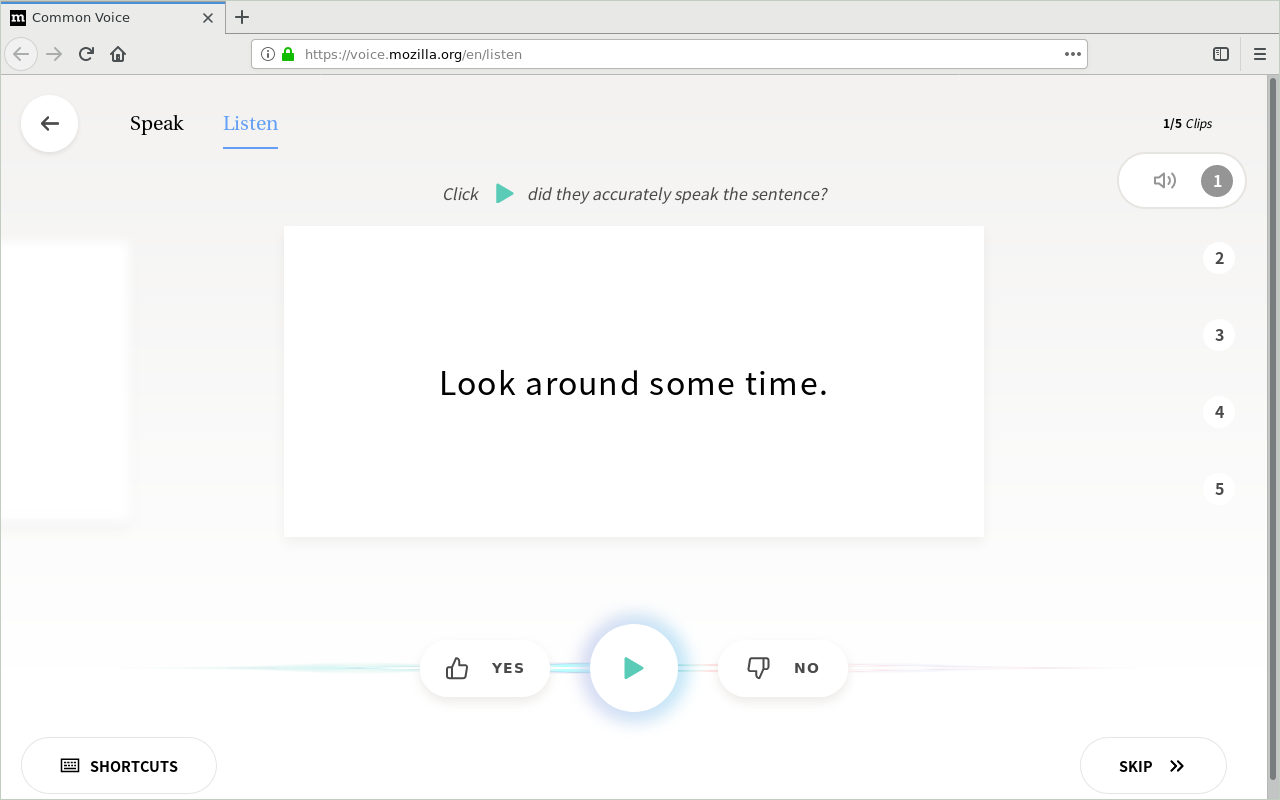
Aside from helping to create an awesome public domain speech corpus, it’s just interesting listening to all the varieties of English other contributors speak.
Another way, if you have an account with Mycroft AI, is to validate wakeword sentences, like the one below.
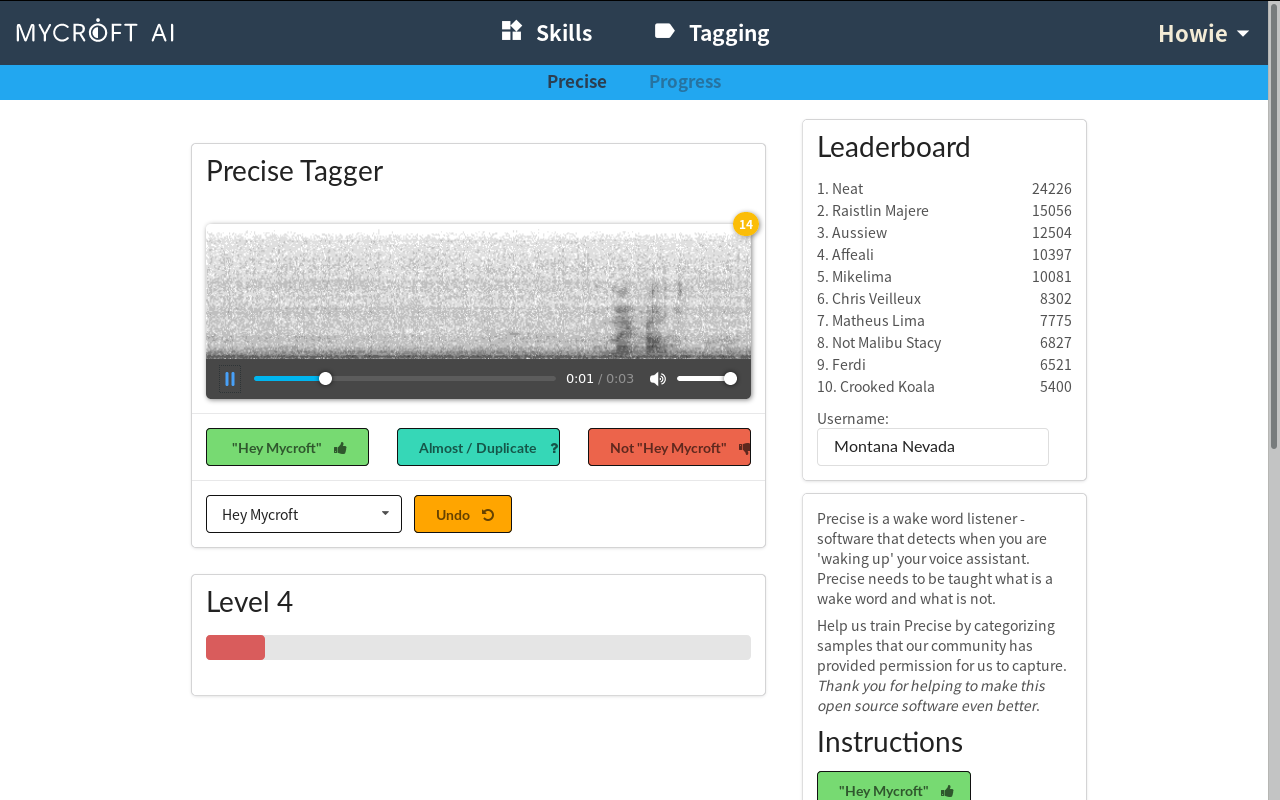
After validating a bunch of sentences I could see that, overall, the default wakeword (“Hey, Mycroft”) is seldom misidentified (leaving my podcast experiences to one side).
Interestingly, other wakewords don’t fare so well. For example, “Athena” generates so many false-positives that I can’t see why anyone would bother using it. In the small sample I was verifying, whenever Mycroft had apparently heard “Athena,” the actual recording was always: a siren outside, some completely unrelated dialogue from a TV, or just muffled static.
Perhaps the Athena mishearings can be attributed to a lack of training data. This is surely part of the equation. But maybe it has to do with the word’s phonetic characteristics. Three vowels, a fricative and a nasal make for a very sonorant utterance - certainly much less distinctive than the stop laden “Hey, Mycroft.” Honestly, I have no idea of the impact this has on speech recognition, but it’s worth noting that the wakewords for both the Google Home (“Okay, Google”) and Amazon Echo (“Alexa”) each include at least one stop.
Closing thoughts
All in all, I’m really digging Mycroft. I’ve already learned a lot sniffing about the documentation and will no doubt continue to as the project grows. I’m no voice assistant convert, but I can really appreciate all the work that’s gone into the project so far. I look forward to seeing what comes next.
“Hey Mycroft, nice work.”